企業 AI 導入指南:從流程盤點、資料治理到正式系統上線

企業開始評估 AI 時,最常見的問題是「要選哪個模型?」但真正決定專案能不能上線的,通常不是模型名稱,而是流程是否清楚、資料能否安全使用、輸出如何驗證,以及系統能不能接回既有工作。AI 導入不是購買一個聊天工具,而是重新設計人、資料與系統如何一起完成任務。
先看結論:企業 AI 導入要同時處理四個層次
- 業務目標:要改善哪個流程,現在的成本、時間與錯誤率是多少?
- 資料與權限:AI 可以讀哪些內容,不同角色能看到什麼?
- 應用與整合:輸入、模型、工具、人工覆核與既有系統如何連接?
- 治理與維運:如何測試品質、記錄操作、控制成本並處理異常?
AI 導入不等於把 ChatGPT 開給所有同事
一般聊天工具適合個人發想與臨時工作,但企業流程通常還需要帳號權限、內部資料、固定輸出格式、審核節點、操作紀錄與系統串接。如果同仁必須反覆複製資料到聊天視窗,再手動整理結果,效率與風險都很難管理。正式應用應該把 AI 放進既有流程,而不是讓每個人自行發明一套使用方式。
哪些工作適合優先導入 AI?
適合的第一批應用通常具備高頻、文字或影像資料量大、目前需要大量人工判讀,且結果可以被人或規則驗證。反過來說,如果流程本身尚未標準化、資料品質差,或錯誤後果無法承受,應先整理流程與治理方式,再決定是否使用 AI。
- 內部知識查詢:從文件、規範與歷史案例中找到有來源的答案。
- 內容工作流:產生文章草稿、摘要、SEO 建議與圖片 Prompt,再由編輯審核。
- 客服與詢問處理:分類需求、整理重點、建議回覆,但保留人工確認。
- 文件與報表:擷取欄位、比較版本、彙整會議與產生固定格式初稿。
- 影像與創意輔助:產生概念稿、素材變體與活動視覺方向,保留品牌審核。
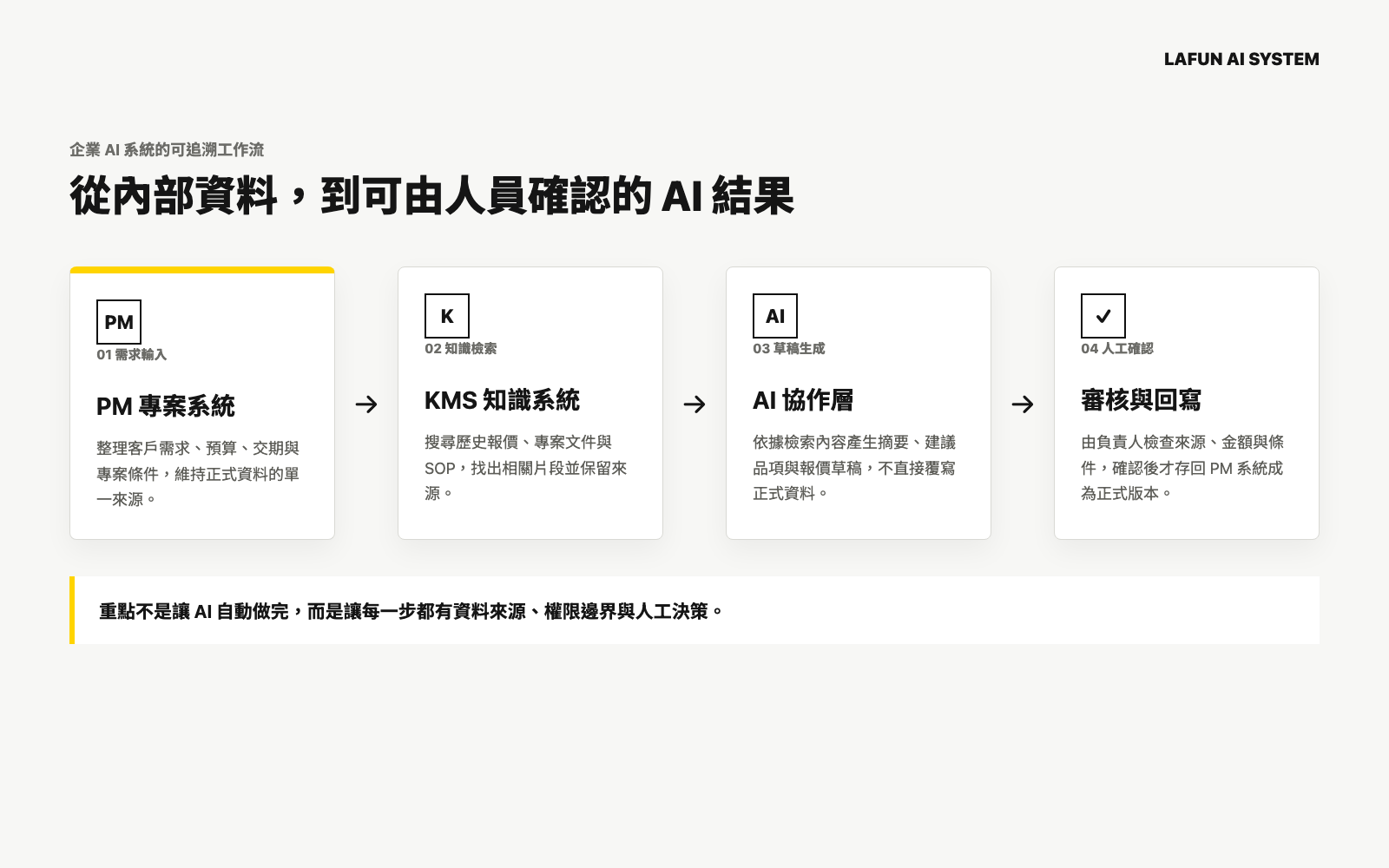
從需求到正式上線的七個步驟
第一步:定義業務問題與衡量基準
不要只寫「導入 AI 提升效率」,而要描述具體工作:誰在什麼情況下,使用哪些資料,花多少時間產生什麼結果。先記錄目前的處理時間、人工成本、錯誤類型與等待時間,才能判斷導入後是否真的改善。
- 錯誤示例:建立一個公司 AI 助手。
- 較好示例:讓業務能在兩分鐘內,從核准的產品文件找到附來源的規格答案,並降低詢問技術人員的次數。
第二步:畫出現在的流程與資料流
列出資料從哪裡進來、誰會處理、經過哪些系統、哪個節點需要核准,以及結果最後存到哪裡。這一步會找出真正的瓶頸,也會揭露個資、客戶資料、合約、未公開內容與不同部門權限。沒有資料盤點,就很難正確設計 AI 權限。
第三步:選擇 SaaS、API 或客製系統
單一部門、低風險且流程接近標準功能時,可以先使用 SaaS;需要將 AI 放進網站、CMS、CRM 或內部系統時,通常會使用模型 API;如果涉及多角色權限、專屬介面、內部知識、審核流程與多系統整合,就需要客製應用。選擇標準不是哪一種比較先進,而是哪一種能符合流程、治理與維運需求。
- SaaS:啟用快,但流程與資料控制受產品功能限制。
- 模型 API:可整合既有產品,但仍需自行建立權限、提示、驗證與監控。
- 客製 AI 系統:可依組織流程設計,開發與維運責任也較完整。
第四步:設計資料檢索與來源顯示
企業知識助手不應只要求模型「記得公司資料」。常見做法是先依使用者權限查找相關文件,再把必要內容交給模型回答,並顯示引用來源。這類檢索增強生成流程可以降低無根據回答,但仍需要處理文件版本、切分方式、權限同步、過期內容與查無資料時的回應。
第五步:建立評估資料與人工覆核
AI 輸出具有變動性,不能只用幾個看起來成功的範例判斷品質。上線前應準備代表真實工作的測試資料,包含正常案例、模糊問題、缺少資料、惡意輸入與權限不足等情境,並定義正確性、完整性、引用品質、格式與拒答條件。高影響輸出必須保留人工確認。
第六步:把安全與權限放進系統設計
生成式 AI 應用除了傳統網站安全,還要處理提示注入、敏感資訊外洩、不安全輸出與過度授權等風險。模型產生的文字、HTML、SQL 或工具參數都不應直接信任;系統必須驗證輸出、限制可執行動作,並沿用原有使用者權限,而不是讓 AI 取得所有資料。
- 只傳送完成任務必要的資料,敏感欄位先遮罩或排除。
- 檢索結果必須依目前登入者權限過濾。
- 所有工具呼叫都使用白名單、參數驗證與最小權限。
- 重要操作在執行前要求使用者再次確認。
- 保存必要的請求、模型版本、結果與人工修改紀錄。
第七步:分階段上線並持續監控
測試原型可以驗證方向,但正式系統還需要登入與權限、錯誤處理、用量限制、成本預警、操作日誌、內容版本、備援與回滾。建議先讓小範圍使用者在真實流程中試用,收集失敗案例後再逐步擴大,而不是完成一次 Demo 就直接開放全公司。
正式 AI 系統通常包含哪些元件?
- 使用者介面:網站、後台、聊天介面或既有系統中的操作入口。
- 應用 API:負責登入、權限、資料驗證、流程狀態與商業規則。
- 模型層:依任務選擇文字、影像或語音模型,並管理版本與參數。
- 知識與資料層:文件、資料庫、搜尋索引、向量檢索與權限資訊。
- 工具整合:CRM、CMS、ERP、Email、檔案系統與內部 API。
- 治理與觀測:日誌、品質評估、人工回饋、成本、延遲與安全事件。
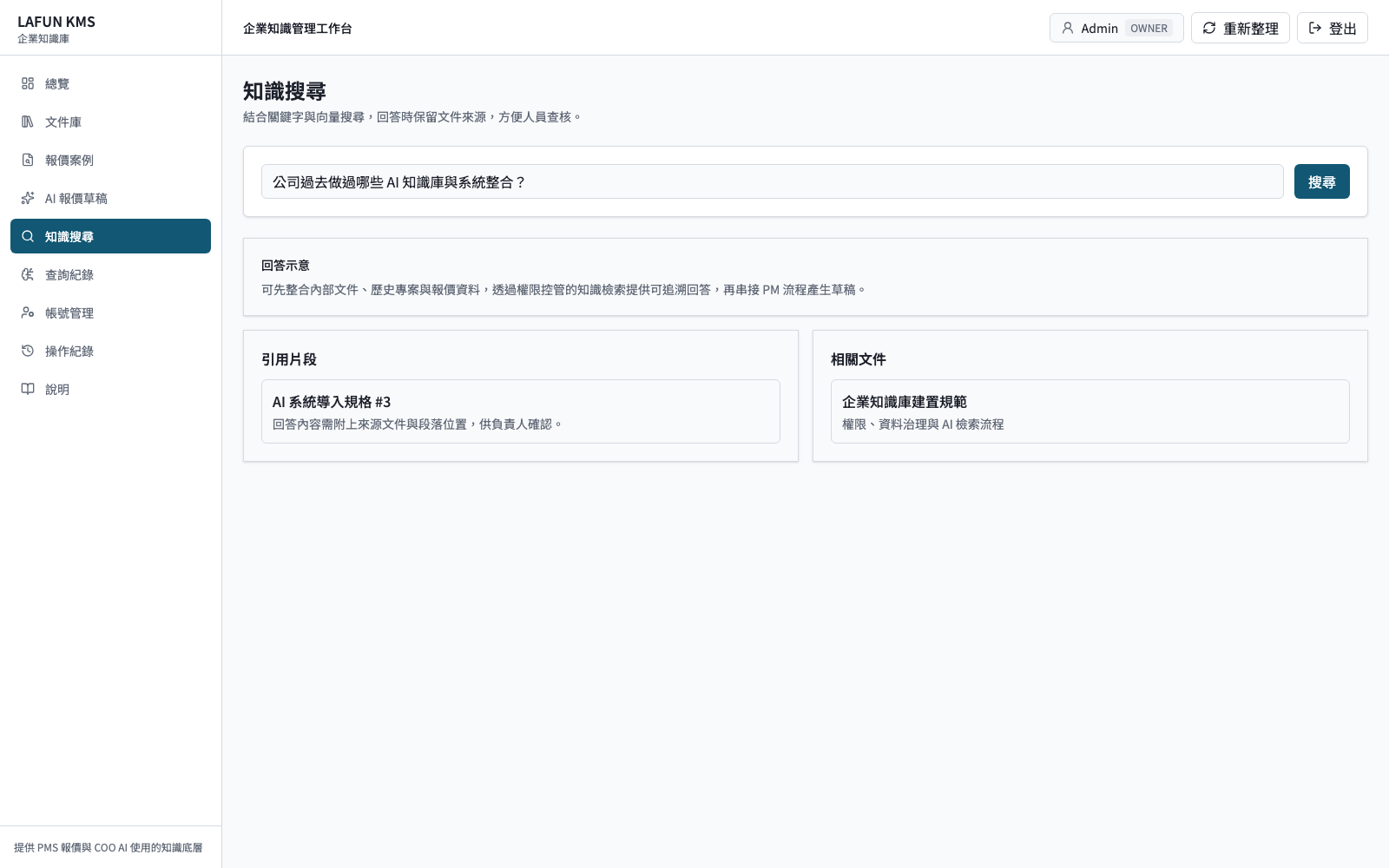
實際應用:KMS 與 PM 系統如何協作
以我們建立的企業知識系統與專案管理系統為例,KMS 統一整理內部文件、歷史報價與專案資料,查詢結果保留引用片段;PM 系統則負責客戶需求、專案條件與正式報價。兩套系統透過受控 API 協作,避免人員把內部資料反覆複製到外部聊天工具。
當業務建立報價需求時,PM 系統把必要條件送至 KMS,搜尋相關案例與文件,再由 AI 產生品項、金額與假設條件的初稿。草稿不會直接成為正式報價,必須由負責人核對來源、調整內容並確認後,才回寫到專案流程。這種設計讓 AI 縮短整理時間,同時保留權限、來源與人工決策。
實際應用:把 AI 放進 CMS 內容流程
以內容後台為例,AI 可以讀取目前文章標題、摘要與內文,協助產生摘要、改寫、SEO 建議及圖片 Prompt。真正重要的不是多一個聊天框,而是 AI 結果可以先預覽,再由編輯決定套用到哪個欄位;圖片產生後進入媒體庫,文章仍遵守草稿、預覽、審核與發布流程。這樣 AI 是既有 CMS 的能力,而不是繞過內容治理的捷徑。
企業 AI 導入成本要看哪些項目?
模型費用通常只是整體成本的一部分。完整評估還應包含需求分析、資料整理、介面、API、權限、既有系統串接、測試資料、人工審核、監控、雲端資源與後續維護。只比較每次模型呼叫價格,容易低估正式上線所需的工程與治理。
- 模型使用量:輸入輸出長度、影像數量、請求頻率與尖峰流量。
- 資料工程:文件整理、欄位清理、權限同步、索引與版本更新。
- 系統開發:前後台介面、API、工作流、通知與第三方串接。
- 品質與安全:測試集、人工評估、日誌、監控、備援與事件處理。
- 營運維護:模型升級、提示調整、內容更新、使用者訓練與成效追蹤。
哪些情況不應該急著使用 AI?
- 流程可以用明確規則穩定完成,AI 反而增加不確定性。
- 沒有可用資料,也沒有負責維護資料的人。
- 錯誤會直接造成重大財務、醫療、法律或安全影響,卻沒有人工覆核。
- 無法定義成功標準,只希望因為市場熱門而加入 AI。
- 組織尚未確認資料能否傳送給外部服務與保存方式。
啟動 AI 專案前的檢查清單
- 寫出一個具體流程、負責角色、輸入資料與預期輸出。
- 記錄目前處理時間、成本、錯誤與等待時間。
- 確認資料擁有者、敏感等級、保存政策與角色權限。
- 準備能代表真實工作的測試案例與拒答案例。
- 定義哪些結果可自動使用,哪些必須人工確認。
- 確認模型、API、資料庫與既有系統的責任邊界。
- 規劃日誌、用量、成本、品質與安全監控。
- 安排分階段上線、使用者回饋與回滾機制。
風險管理可參考哪些標準?
NIST AI Risk Management Framework 提供組織在 AI 設計、開發、使用與評估過程中管理風險的框架;生成式 AI Profile 則補充生成式 AI 的特有風險。OWASP Top 10 for LLM Applications 整理提示注入、敏感資訊揭露、不安全輸出處理與過度代理權限等常見應用安全問題。
常見問題
應該先決定使用哪一個模型嗎?
不建議。先定義任務、資料、品質、延遲、成本與安全需求,再以測試資料比較模型。模型可以更換,但流程與資料治理若沒有設計好,更換模型也不會解決問題。
公司資料一定要拿去訓練模型嗎?
不一定。許多企業知識應用使用檢索方式,在收到問題後才取得使用者有權查看的文件片段,不需要重新訓練基礎模型。是否微調模型應依任務、資料量與評估結果決定。
先做 PoC 就可以直接上線嗎?
不行。PoC 可以驗證模型是否有能力完成任務,但正式上線仍要補上權限、安全、錯誤處理、監控、成本、使用者體驗與維運流程。較好的做法是在 PoC 階段就定義正式架構與驗收標準,避免原型變成無法維護的正式系統。
從一個可衡量的流程開始
企業不需要一次把所有工作 AI 化。選擇一個高頻、有資料、可以驗證結果的流程,先完成需求、權限與成效基準,再決定模型與系統架構。如果正在評估知識助手、內容流程、客服分類或既有系統 AI 整合,可以聯絡我們討論導入範圍。