企業 AI 知識庫怎麼做?RAG、權限、資料更新與導入流程

企業累積了大量 SOP、合約、報價、產品文件與專案紀錄,但真正需要資訊時,員工仍可能在資料夾、Email、聊天記錄與不同系統之間反覆搜尋。AI 知識庫的價值不是讓模型讀過所有文件,而是讓使用者能在正確權限下,快速取得附有來源、可以查核,也能持續更新的答案。
先看結論:企業 AI 知識庫要處理六件事
- 文件從哪裡來,誰負責內容與更新。
- 文件如何解析、切分、加入欄位與建立索引。
- 不同角色與部門可以搜尋哪些資料。
- 如何找出相關片段,而不是把所有文件一次交給模型。
- 回答如何顯示來源、處理查無資料與保留人工確認。
- 如何評估品質、記錄使用情況並持續維運。
AI 知識庫不等於上傳文件後開始聊天
一般文件問答工具可以快速驗證概念,但企業正式使用時還需要登入、角色權限、文件版本、有效日期、來源引用、刪除同步、操作紀錄與品質監控。如果離職員工、不同部門或外部協力廠商都能搜尋到同一批內容,即使回答再準確,也不是可上線的企業系統。
哪些情境適合先導入?
- 產品與客服知識:查詢規格、流程、常見問題與核准回覆。
- 內部制度與 SOP:依部門與角色取得最新作業方式。
- 專案與歷史案例:搜尋過往需求、解法、交付內容與注意事項。
- 報價與提案輔助:從歷史品項、條件與文件產生可供人工確認的草稿。
- 文件比較與摘要:整理版本差異、會議重點與指定格式初稿。
開始前先整理資料責任
知識庫品質上限通常由原始資料決定。若文件重複、過期、沒有擁有者,AI 只會更快地把混亂呈現給使用者。建立索引前,應先確認每類文件的擁有者、有效日期、機密等級、更新方式與下架規則。
- 列出資料來源:雲端硬碟、檔案伺服器、資料庫、CMS、CRM 或內部 API。
- 標記內容擁有者與審核人,避免沒有人負責更新。
- 定義公開、內部、部門、專案與個人等存取範圍。
- 確認個資、客戶資料、合約與機密內容能否進入模型流程。
- 訂出文件更新、過期與刪除後的索引同步方式。
企業 AI 知識庫的完整架構
正式架構可以分成資料建置與問答兩條流程。資料建置負責把內容變成可搜尋、可治理的知識;問答流程則先確認使用者身分與權限,再搜尋相關片段並生成回答。兩者都需要日誌、版本與品質評估。

第一部分:文件解析、切分與索引
PDF、Word、試算表、網頁與資料庫的結構不同,不能只把檔案名稱存進系統。解析後應保留標題、章節、日期、客戶、專案、文件類型與權限等欄位,再依語意與段落切成適合檢索的片段。切得太小會失去上下文,切得太大則容易混入無關內容。
第二部分:關鍵字、向量與混合檢索
關鍵字搜尋適合專有名詞、編號與精確名稱;向量搜尋適合使用者用不同說法描述同一概念。企業知識庫通常需要混合使用,再利用文件類型、日期、專案與權限條件縮小範圍。檢索的目標不是找最多內容,而是找出足以支持回答的少量可靠片段。
第三部分:權限必須在檢索前過濾
不能先搜尋所有資料,再要求模型不要提到機密內容。系統應沿用登入者的角色、部門、專案與文件權限,在查詢階段就排除無權查看的片段。管理者也需要能追蹤文件權限變更後,索引是否同步更新。
第四部分:回答、來源與拒答
回答應附上文件名稱、片段或可開啟的來源連結,讓使用者知道資訊從哪裡來。當檢索結果不足、來源互相矛盾、文件過期或使用者沒有權限時,系統應清楚說明無法回答,而不是用通順文字補完未知內容。
知識怎麼持續更新?
- 事件同步:文件新增、修改、刪除或權限變更時立即更新索引。
- 排程同步:定期掃描資料來源,適合變更頻率較低的文件庫。
- 版本管理:保留生效時間與舊版關係,避免搜尋到已失效內容。
- 內容治理:提供待審核、已發布、已封存等狀態。
- 失敗處理:解析或索引失敗時要能重試、告警並保留紀錄。
上線前怎麼測試知識庫品質?
不要只用幾個成功問題展示。應從真實工作蒐集測試題,包含正確答案、預期來源、無答案、權限不足、模糊問題與惡意指令,分別評估檢索是否找到正確片段、回答是否忠於來源,以及系統是否在不該回答時拒答。
- 檢索命中率:正確來源是否出現在前幾筆結果。
- 回答正確性:內容是否能由引用片段支持。
- 引用品質:來源是否對應到實際答案,而不是只有相關主題。
- 權限測試:不同角色是否只能看到被授權內容。
- 拒答表現:查無資料與敏感要求是否能安全處理。
- 使用體驗:回應時間、來源開啟與回饋流程是否可接受。
安全與提示注入不能忽略
文件本身也可能包含要求模型忽略規則、洩露資料或執行動作的文字。檢索內容應視為不可信輸入,不能因為來自內部文件就直接允許工具操作。系統需要限制模型可用工具、驗證輸出、遮罩敏感資料,並要求重要動作再次確認。
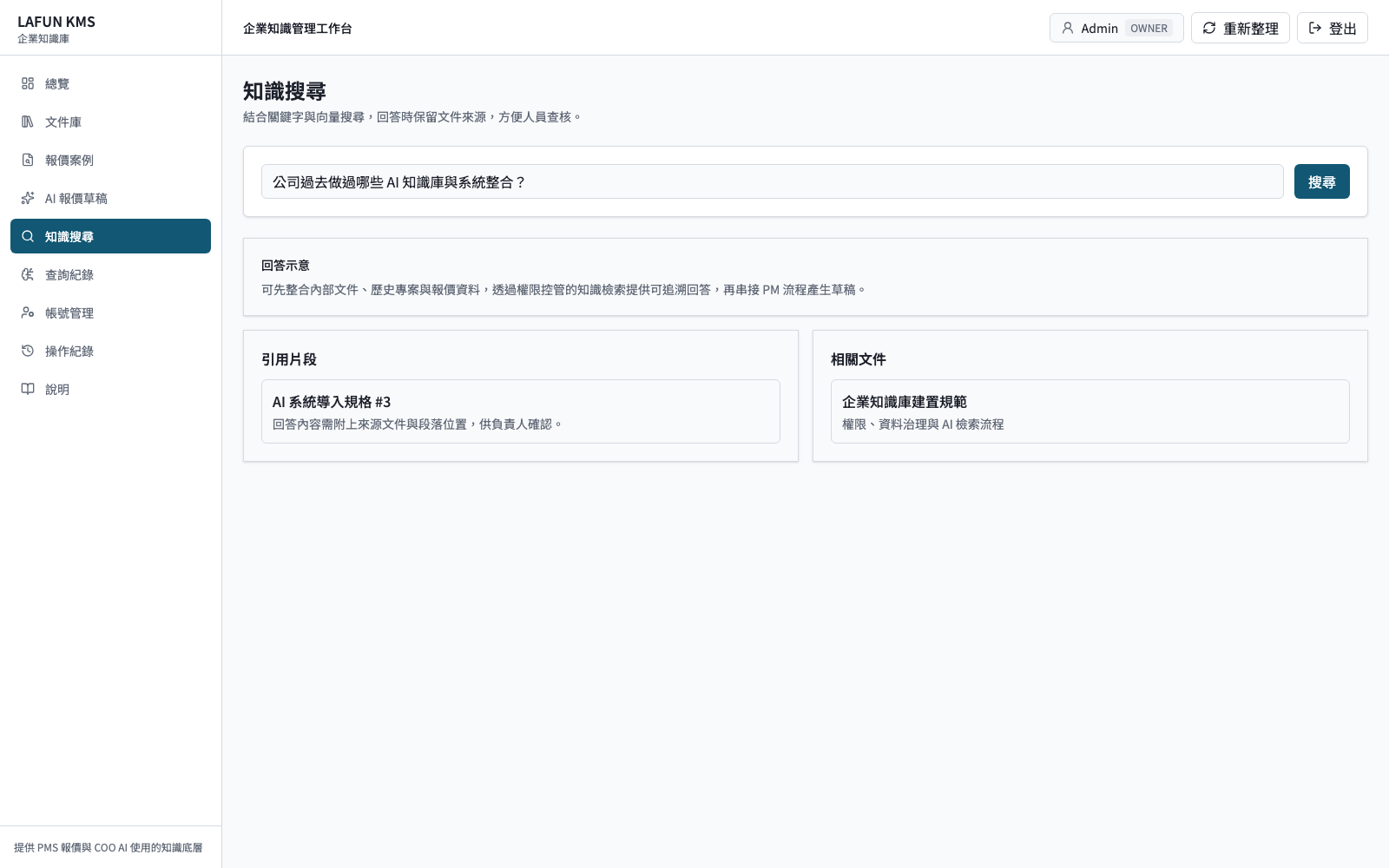
實際介面應讓使用者查核來源
以企業知識搜尋介面為例,回答區之外還應顯示引用片段與相關文件。管理端則要能查看查詢紀錄、命中來源、使用者回饋與失敗問題,讓內容負責人知道哪些資料需要補充或修正。
建議的導入步驟
- 選一個高頻、資料相對完整且可由人驗證的使用情境。
- 盤點文件來源、擁有者、權限、版本與敏感內容。
- 建立小型測試集,先驗證解析、檢索與引用品質。
- 完成登入、權限、來源顯示、拒答與操作紀錄。
- 讓小範圍使用者試用,蒐集找不到與回答錯誤的案例。
- 建立更新、監控、成本與內容治理後,再逐步擴充資料範圍。
導入成本包含哪些部分?
- 資料盤點、清理、欄位與權限設計。
- 文件解析、切分、索引與更新管線。
- 搜尋、向量資料庫、模型 API 與運算資源。
- 前後台介面、登入、權限、來源與回饋功能。
- 評估資料、測試、安全、日誌與監控。
- 內容維護、模型調整、使用者訓練與後續整合。
延伸參考
- Retrieval-Augmented Generation 原始論文
- NIST AI Risk Management Framework
- OWASP Top 10 for LLM Applications
常見問題
公司文件一定要拿去訓練模型嗎?
不一定。許多知識庫使用檢索方式,在收到問題時才取得有權查看的文件片段,不需要重新訓練基礎模型。是否微調模型應依任務、資料量與測試結果決定。
把雲端硬碟接上 AI 就完成了嗎?
還不夠。正式系統仍需要處理解析失敗、文件版本、角色權限、刪除同步、來源顯示、品質測試與操作紀錄。
RAG 可以完全避免 AI 回答錯誤嗎?
不能。RAG 能提供外部知識與來源,但仍可能檢索錯誤、誤解片段或產生不被來源支持的文字,因此需要測試、引用、拒答與人工確認。
從一個可驗證的知識任務開始
先選擇一類有明確負責人、使用頻率高,也能判斷答案是否正確的文件,完成權限、來源與測試流程,再逐步擴大知識範圍。如果正在規劃內部知識搜尋、客服知識庫或 AI 報價輔助,可以聯絡我們討論資料與系統架構。